论文精读 · 组会汇报
扩展时点语言模型
(Scaling Point-in-Time LLMs)
作者简介
研究团队
四位作者横跨学界与业界,共同代表了"AI + 量化金融"这一交叉方向的核心力量。
Frederick Frank '54 讲席教授(Yale SOM),AQR 机器学习负责人(Principal)。曾为 Chicago Booth 终身教授,NYU Stern 金融学博士。
研究核心是资产定价 × 机器学习 × 金融计量,代表性工作包括 IPCA(Instrumented PCA)因子模型、Artificial Intelligence Asset Pricing Models(AIPM,用 Transformer 构造 SDF),论文发表于 JF、AER、QJE、JFE、RFS。
SFI 终身教授,同时兼任 BIS(国际清算银行)与欧洲央行 Lamfalussy 研究员,Journal of Finance 副编辑。曾获 INQUIRE Europe/UK 研究奖、Dauphine-Amundi 资产管理奖。
研究横跨均衡资产定价、ETF 市场微观结构、机器学习理论;2015 年提出首个 ETF 均衡定价模型;近年深入 AI 定价模型与 NTK(神经切线核)的金融应用。
EPFL 金融工程硕士毕业后,先在 Taranis 任量化分析师(Geneva),2023 年 9 月加入 Malamud 课题组攻读博士。本文是其博士阶段的早期核心成果之一。
研究聚焦机器学习理论在金融中的应用,合作论文还包括 "Training NTK to Generalize with KARE"(NTK 泛化理论)、"A Test of the Efficiency of a Given Portfolio in High Dimensions"(与 Chernov、Kelly 合作)。
2024 年 6 月以 EPFL 博士身份(Malamud 指导、SNSF 资助)加入 AQR 整合研究团队,与 Kelly 并肩工作;此前曾以访问博士生身份在耶鲁随 Kelly 研究。意大利人,本科 + 硕士在罗马 La Sapienza(计算机工程)。
背景横跨 CS 与金融:论文涵盖AI 资产定价(AIPM)、隐含波动率曲面深度学习、DeFi 协议,在 NBER 工作论文与 JF、RFS 合作项目中均有贡献。
团队结构的意义
这个团队的组合并非偶然——Kelly 和 Malamud 已合作多年(AIPM、IPCA 等),Xu 是从 Malamud 门下直接进入 AQR 的博士,Schwab 是 EPFL 本地的博士生执行力量。学界 ↔ 业界双向通道(AQR 提供计算资源与金融数据,EPFL 提供 CSCS 超算)是这类大规模训练实验能够落地的关键。
Section 1
研究背景:时间泄露的陷阱
为什么不能直接用通用 LLM 做金融回测?
什么是 Lookahead Bias?
当你用 GPT-4 或 LLaMA 分析 2018 年的新闻来预测股价时,这些模型的训练数据实际上涵盖了 2018 年之后发生的一切——公司后续发展、行业演变、历史评价。这种"知道未来"的信息渗透到模型的每一个参数里,使回测结果虚高,因果推断失效。
⚠ 真实危害
Glasserman & Lin (2023) 证明,用 GPT 生成的情绪分析预测股票收益时,如果不控制时间泄露,Sharpe 比率会被显著高估。Lopez-Lira & Tang (2023) 的 ChatGPT 情绪信号研究同样受到这一质疑。两项有代表性的工作都因此需要重新审视其结论的效度。
现有方案的困境
解决方法直觉上很简单:训练时只用"那个时间点之前"的数据,生成一系列月度快照模型(point-in-time checkpoints)。
已有工作(ChronoBERT / ChronoGPT / DatedGPT)验证了可行性,但这些模型的参数规模被限制在 1.5B 以内,性能与最前沿开放模型相差悬殊。研究者面临两难:要可信度还是要性能?
🎯 本文核心主张
性能差距本质上是规模差距,而非时间约束的内在限制。通过将规模推进到 4B 参数 + 1T token,性能损失可以大幅收窄,让"时间有效"和"性能强劲"不再互斥。
论文的四大贡献
Section 2
方法论:三阶段训练流程
从时间过滤数据到月度快照,再到指令跟随微调。
模型架构
基于 GPT 架构的纯解码器 Transformer,两个规格:
170B token 训练
1T token 训练
2013.05 → 2024.12
架构上引入了多项现代优化:Shampoo 分布式优化器(二阶梯度)、值残差学习(来自 Gemma 2)、学习率现代化。训练目标是标准的自回归下一 token 预测:
预训练数据:FineWeb 的时间切片
选用 FineWeb(HuggingFace,2013–2025,15 万亿英文 token)。FineWeb 本身带有发布时间戳,可以按时间截断,无需额外标注。按时间顺序流式喂入模型,每月保存一次检查点——这与持续学习(Continual Learning)文献的增量训练框架高度对齐。
指令微调:LoRA 与时间过滤
给定预训练权重矩阵 $W_0$,LoRA 冻结 $W_0$,仅学习低秩分解的更新量:
💡 为什么用 LoRA 而非全参数微调?
三个理由:① Biderman et al. (2024) 证明 LoRA 是隐式正则化器,抑制灾难性遗忘;② 可训练参数减少两个数量级($r=16$ 时),GPU 需求大幅下降;③ 在适当调参下性能与全参数微调仅差 1–2%。对于需要跨时间保持一致性的 PIT 场景,防止灾难性遗忘尤其重要。
表1:训练数据集详解
| 阶段 | 数据集 | 原始量 | 过滤后 | 过滤率 |
|---|---|---|---|---|
| PT | HuggingFaceFW / fineweb | 1T token | — | 按时间戳直接截断 |
| SFT | evol_codealpaca(代码) | 106,790 | 100,114 | 6.2% 去除 |
| SFT | personahub_code(代码) | 34,943 | 34,748 | 0.6% 去除 |
| SFT | tulu_v3.9_gsm8k(数学) | 50,000 | 49,772 | 0.5% 去除 |
| SFT | numinamath_tir(数学) | 64,191 | 63,910 | 0.4% 去除 |
| SFT | personahub_ifdata(指令) | 29,827 | 25,293 | 15.2% 去除 |
| SFT | argilla / IFEval-like(指令) | 456,304 | 270,000 (上限截断+过滤) |
~15% 去除 |
深度解读 · 表1
① 代码 / 数学数据几乎不受时间影响(过滤率 <1%)
冒泡排序不会因为 2023 年发生了什么而改变;费马大定理也不是当年新闻。数学和代码知识的时间无关性使得这类数据几乎全部通过时间过滤,也解释了为什么 PIT 模型在推理型任务上表现接近无限制模型。
② 指令跟随数据过滤率最高(~15%)
persona_ifdata 和 argilla/IFEval-like 的过滤比例达到 15%,远高于代码和数学。原因在于:指令响应数据中大量引用了具体事件、人物、机构——这些内容极易带入时间戳之后的信息。这说明"时间一致的指令微调"是真实存在的工程挑战,不是可以随意跳过的步骤。
③ 数据总量的策略平衡
将 argilla/IFEval-like 截断到 270k 是有意为之:约一半数据用于代码+数学(需要准确性),另一半用于指令跟随(需要格式遵守)。这种比例设计反映了对 IFEval 评测维度的针对性适配。
⚠ 潜在批评
SFT 数据集全为英文,且主要覆盖代码/数学/指令遵守,对金融领域的适应性微调几乎为零。这意味着 SFT 对提升 Section 4.3 金融应用的贡献,很可能来自更好的文本表示质量,而非领域专业知识。
Section 3
NLP 基准评测:缩小性能差距
零样本常识推理与语言理解——时间约束下的模型能做到什么?
图1:HellaSwag 准确率随时间演化
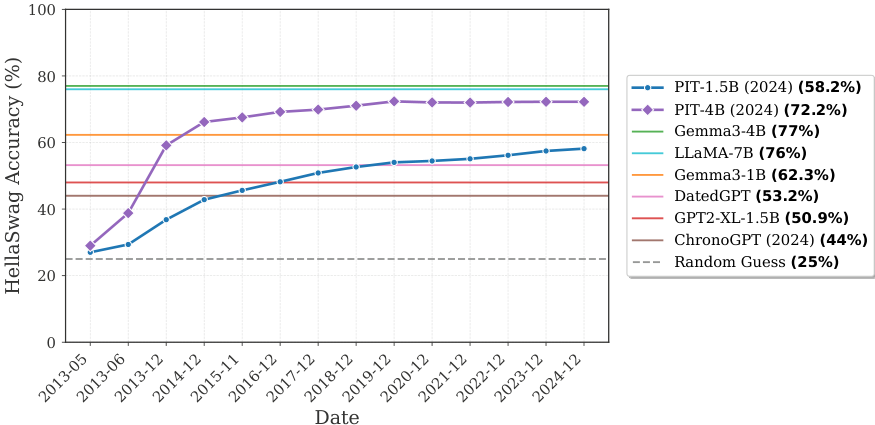
深度解读 · 图1
① 这张图本身是一个思想实验
图中每个检查点回答的问题是:"如果我的知识在 XXXX 年截止,我的推理能力是多少?" 横轴不是训练步数,而是历史时间——这种设定在 LLM 研究里几乎绝无仅有,也是 PIT 研究的核心设计。
② 三个阶段的演化规律
2013.05–2014.06(快速起步期):PIT-4B 从约 28% 快速升至 68%,增幅达 40pp。这对应着互联网文本最密集的学习阶段——模型见到的 token 数从 0 增至数百亿,每增加一批数据的边际贡献极大。
2014.06–2018.12(稳步提升期):上升斜率放缓,每年约 +1–2pp。此时模型已建立起基础语言能力,新数据主要是在"精细化"而非"从头学习"。
2019–2024(收益递减期):曲线趋于平坦,PIT-4B 在 72%–73% 附近徘徊。这与 Kaplan 等人 Scaling Law 中描述的"数据饱和效应"一致。
③ 参照线的战略意义
图中设置了三类对比锚点,需要从金融+ML 双视角理解:
- ▲ ChronoGPT 2024(44%)/ DatedGPT(53.2%):当前 PIT 模型的"天花板"。PIT-4B 将这个天花板从 53% 推进到 72%,提升幅度高达 19pp。
- ▲ Gemma-3-4B(77%)/ LLaMA-7B(76%):无时间限制对手的性能上界。差距已从约 30pp(ChronoGPT vs LLaMA)缩小到约 4pp(PIT-4B vs LLaMA-7B)。
- ▲ Gemma-3-1B(62.3%):参数量是 PIT-4B 的 1/4 的现代全样本模型。PIT-4B 已经超越了它(72.2% vs 62.3%),说明规模扩展完全可以弥补时间约束。
实证应用层面
- 2013 年起就有可直接使用的月度 PIT 检查点
- 性能曲线平稳上升,无突变点,可放心接入历史分析管线
- 覆盖 2013–2024,适合构建十年级别的文本因子回测
- "有偏但强"与"无偏但弱"的权衡,在 4B 规模下基本消失
方法论层面
- Scaling Law 在时间约束范式下同样成立
- 持续预训练(continual pre-training)框架完全适用
- ~4pp 剩余 gap 来自知识密度差异,非架构瓶颈
- 开放方向:时间感知位置编码、领域专项持续学习
表2:七项基准零样本准确率全面对比
| 模型 | BoolQ | PIQA | HellaSwag | WinoGrande | ARC-Easy | ARC-Chal. | OBQA | 平均 |
|---|---|---|---|---|---|---|---|---|
| DatedGPT2024 | — | 70.5 | 53.2 | — | 52.0 | 34.7 | — | 52.6 |
| ChronoGPT2024 | 60.4 | 66.5 | 43.9 | 54.9 | 52.5 | 29.5 | 34.8 | 48.9 |
| PIT-1B2024(ours) | 61.9 | 76.1 | 64.3 | 59.4 | 49.5 | 30.4 | 34.8 | 53.8 |
| PIT-4B2024(ours) | 63.0 | 78.9 | 72.2 | 64.2 | 54.4 | 35.1 | 39.0 | 58.1 |
| Gemma-3-1B(参照) | 66.4 | 74.8 | 62.0 | 58.9 | 72.2 | 38.3 | 37.0 | 58.5 |
| Gemma-3-4B(参照) | 79.0 | 80.0 | 76.0 | 69.5 | 81.8 | 54.9 | 43.0 | 69.2 |
| LLaMA-7B(参照) | 76.8 | 79.7 | 76.0 | 69.6 | 72.1 | 44.3 | 44.4 | 66.1 |
深度解读 · 表2
① "推理型"任务 vs "知识型"任务——时间约束影响完全不同
这是表2最值得深挖的结构性规律。把七项任务按"知识依赖度"分类:
| 任务类型 | 代表任务 | PIT-4B vs LLaMA-7B 差距 | 背后原因 |
|---|---|---|---|
| 纯推理型 | PIQA、WinoGrande | ≈0.8–5.4pp(几乎持平) | 物理常识/共指消解不依赖时间 |
| 中间型 | HellaSwag、OBQA | 3.8–5.4pp | 部分依赖文化/世界知识 |
| 知识密集型 | BoolQ、ARC-easy | 13.8–27.4pp(差距显著) | 需要大量事实性知识积累 |
② PIT-4B 与 Gemma-3-1B 几乎打平(58.1 vs 58.5)
Gemma-3-1B 是参数量仅为 PIT-4B 四分之一的现代全样本模型,却与 PIT-4B 平均得分相差不到 0.4pp。这一对比极具说服力:参数量 4× 的时间约束模型,与参数量 1× 的无约束现代模型性能相当,且两者在 PIQA、WinoGrande 等推理任务上差距已接近 0。
③ ARC-easy 的大差距需要特别关注(54.4 vs 81.8,差 27pp)
ARC 测试的是小学科学知识。这类知识高度依赖知识广度而非推理深度。在时间约束下,PIT-4B 见过的训练文本总量(1T token)虽然已经很大,但覆盖科学事实的文本比例可能仍不足。此外,全样本模型(如 Gemma-3-4B)的训练数据中包含大量科学教材和维基百科,而 FineWeb 主要是网页文本,这种数据构成差异也在 ARC 任务上显现。
🔍 对金融研究者的关键含义
金融文本分析任务(新闻情绪、事件识别、主题聚类)的认知特征更接近"推理型"而非"科学知识测试"——这意味着 PIT-4B 在金融应用中的性能劣势,可能比 ARC 任务暗示的要小得多。Section 4.3 的资产定价实验将直接验证这一推断。
Section 4
指令跟随:LoRA 微调的效果
用 IFEval 评测——避免 LLM-as-judge 的系统性偏差。
为什么不用 AlpacaEval / GPT-4 打分?
LLM 作为评判者存在三大已记录偏差:
- 自我偏差:评判者倾向于给和自己风格相似的回答高分
- 位置偏差:先出现的回答更容易获胜
- 冗长偏差:更长的回答被认为更好
Zheng et al. (2024) 甚至证明,一个输出"恒定无关响应"的"空模型"也能在 AlpacaEval 上拿高分。IFEval 避免了这些问题——它测试的是"是否包含关键词"、"是否在字数限制内"等可以用代码程序化验证的约束。
图2:IFEval 指令跟随准确率
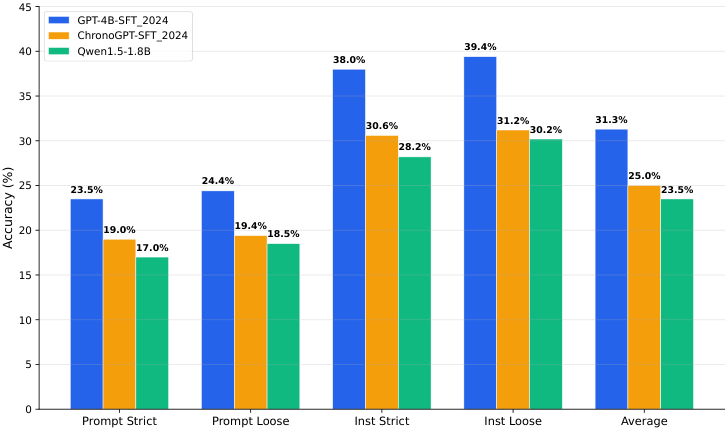
深度解读 · 图2
① 四个维度的含义:两个正交轴
| 维度 | 含义 | PIT-4B | ChronoGPT | Qwen |
|---|---|---|---|---|
| Prompt Strict | 整个 prompt 的所有约束均严格满足 | 23.5% | 19.0% | 17.0% |
| Prompt Loose | 整个 prompt 的约束允许小错误 | 24.4% | 19.4% | 18.5% |
| Instruction Strict | 单条指令级别严格满足(多条取均值) | 38.0% | 30.6% | 28.2% |
| Instruction Loose | 单条指令级别允许小错误 | 39.4% | 31.2% | 30.2% |
| 平均 | 31.3% | 25.0% | 23.5% |
② 关键差异:Prompt 级 vs Instruction 级
注意 Prompt 级别得分(~24%)远低于 Instruction 级别(~38%)。这并不矛盾——每个 prompt 通常包含多条指令,只要有一条不满足,Prompt-level 就失败;而 Instruction-level 是对每条指令单独判断再平均。Prompt-level 的低分揭示了一个真实能力缺口:模型可以遵守单条约束,但同时追踪和满足多条约束的能力仍有限。
③ PIT-4B 在 Instruction Strict 上优势最显著(+7.4pp vs ChronoGPT)
这个维度对"遵循精确格式要求"的测试最为严格。PIT-4B 在此超越 ChronoGPT 最多,说明规模扩展对于"精确遵守约束"这一能力的提升最为显著——这与 scaling law 在 instruction following 任务上的一般规律一致。
💡 绝对值的解读:31% 不低
即使是 GPT-4 在 IFEval 上的得分也仅约 77–85%(取决于版本和评测配置)。在 ~3B 参数规模的开放模型中,能达到 31% 平均分已属较好水平。更重要的是,PIT-4B 在指令跟随上的排名优于同类 PIT 模型和 Qwen1.5-1.8B,证明时间一致的 LoRA 微调并未显著损害指令遵从能力。
Section 5
金融经济应用:这些模型真的有用吗?
从新闻嵌入到股票组合——用 Sharpe 比率衡量经济价值。
方法:文本因子 → 投资组合
核心思路是将语言模型的最后一层隐状态作为新闻"嵌入",从这些嵌入中提取投资信号:
- 嵌入生成:用滚动 PIT 模型(年末检查点)为当年新闻生成嵌入。严格禁用未来模型处理历史数据。
- 残差化:对嵌入做横截面回归,去除已知风格因子(Jensen et al. JKP 特征集),保留"纯新闻信息"。
- 构建基础组合:每个嵌入维度对应一个多空组合(高值股票做多,低值股票做空),共 $d_h = 4096$ 个基础组合。
- MSRR 聚合:用最大夏普比率回归(正则化)在扩展窗口上自适应地组合这 4096 个因子。
🔑 为什么用 MSRR 而不是普通回归?
当基础因子数量($P=4096$)远超观测时间长度($T \approx 120$ 月)时,普通 OLS 严重过拟合。MSRR 等价于在 Sharpe 比率目标下做岭回归,$z$ 参数控制收缩强度,并在 grid 上做集成,避免依赖单一调参结果。这是资产定价机器学习文献中的标准稳健做法(Kelly & Xiu 2023)。
图3:样本外年化夏普比率
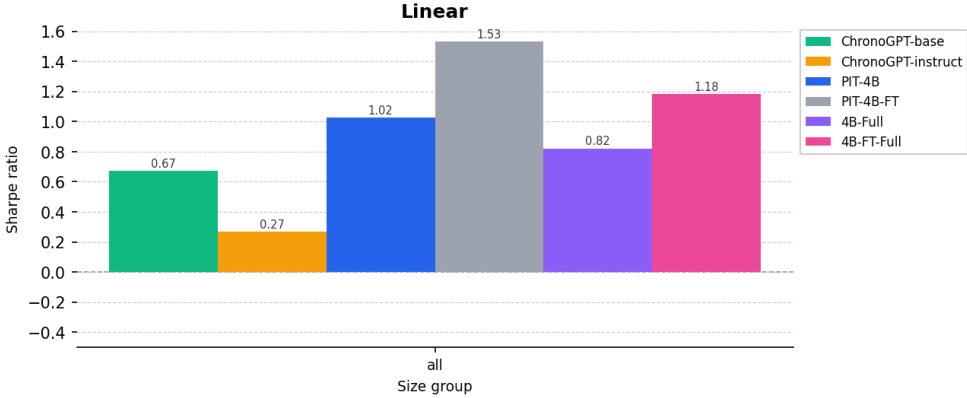
深度解读 · 图3
这张图包含了本文最令人惊讶的结论,从左到右逐一解析:
| 模型 | Sharpe | 时间约束? | 指令微调? |
|---|---|---|---|
| ChronoGPT-base | 0.67 | ✅ 是 | ❌ 否 |
| ChronoGPT-instruct | 0.27 | ✅ 是 | ✅ 是 |
| PIT-4B(ours) | 1.02 | ✅ 是 | ❌ 否 |
| PIT-4B-FT(ours) | 1.53 | ✅ 是 | ✅ 是 |
| 4B-Full(参照) | 0.82 | ❌ 否 | ❌ 否 |
| 4B-FT-Full(参照) | 1.18 | ❌ 否 | ✅ 是 |
① 最惊人发现:PIT-4B(1.02)> 4B-Full(0.82)
严格时间约束的模型反而比有 lookahead 的全样本模型更好预测收益!这颠覆了"lookahead bias 会让模型'学到'更多从而更好预测"的直觉。一个可能的解释:全样本模型的参数中混入了"未来事件的编码",这反而成为噪声,让嵌入向量携带了与当前时点不一致的信息,降低了横截面区分度。
② 规模扩展的效果是戏剧性的
→ PIT-4B-FT
提升 +1.26
→ PIT-4B
提升 +0.35
→ PIT-4B-FT
LoRA 微调增益 +0.51
③ 小模型微调有害,大模型微调有益
ChronoGPT-instruct(0.27)远低于 ChronoGPT-base(0.67)——小模型在指令微调后嵌入质量显著下降,这与 Biderman et al. (2024) 关于小模型更容易发生灾难性遗忘的观察一致。而 PIT-4B 则正好相反:微调后 Sharpe 从 1.02 跃升至 1.53。这说明指令微调对嵌入质量的影响与模型规模强烈正相关。
🔍 深层机制推测
为什么 SFT(在代码/数学/指令数据上)会提升金融新闻嵌入的预测能力?一种解释:指令微调让模型更好地"理解"文本的语用结构(what is asked, what is answered),这种能力迁移到了新闻理解——模型不仅捕捉词汇语义,还更好地理解新闻的信息密度和重要性层级。但这一机制仍是猜测,需要消融实验验证。
⚠ 结论的局限性
图3仅展示"all"规模组的结果,原论文提到在"mega-cap"细分中优势更大,但在所有规模组的完整分解图未在此版本中展示。此外,数据仅到 2020 年 5 月(道琼斯数据集的覆盖范围),2020–2024 年 COVID 后的市场结构变化下是否仍有效,是开放问题。
Section 6
结论与批判性讨论
本文的核心贡献、遗留问题,以及对未来研究的启示。
三条核心结论(可以直接带走)
- 1️⃣ 规模可以弥补时间约束:4B 参数 + 1T token 的 PIT 模型,在常识推理上与 LLaMA-7B 差距仅 4–8pp,基本消除了"无偏 vs 强性能"的取舍困境。
- 2️⃣ 时间有效性在金融中有真实价值:PIT-4B-FT 的 Sharpe 比率(1.53)不仅高于全部 PIT 基线,还超过了同规模的全样本模型(1.18)。训练数据里混入的未来信息,在这里成了干扰——让嵌入向量携带了与当前时点不一致的信号,反而削弱了横截面区分度。
- 3️⃣ LoRA 微调在大模型上是增益,在小模型上是损失:这一规模依赖性警告未来研究者不能盲目在小 PIT 模型上做 SFT,需要先确认规模门槛。
未解决的问题与局限
已知局限
- ARC-easy 差距(~27pp)尚未解决
- 数据集仅到 2020 年 5 月
- 仅在一个金融数据集上验证
- SFT 数据无金融领域内容
- 2022–2025 评测结果缺失
未来方向
- 时间感知 tokenizer / 位置编码
- 金融领域 SFT(财报、研报)
- 多语言 PIT 模型(中文金融)
- 更强的时间过滤:检测隐性 lookahead
- 偏好对齐(RLHF)的 PIT 版本
💡 对我们研究组的参考意义
如果你在用 LLM 分析新闻情绪/公告文本做金融研究,本文提供了两个可直接使用的资源:① Hugging Face 上的月度 PIT 模型检查点(2013–2024),② 完整的 FineWeb 时间过滤 + MSRR 投资组合构建代码。在中国 A 股/港股情境下直接套用可能需要重新训练(中文、不同数据源),但方法论框架是高度可借鉴的。
论文信息: Bryan Kelly, Semyon Malamud, Johannes Schwab, Teng Andrea Xu, "Scaling Point-in-Time Language Models," SSRN Working Paper 6681860, 2026.
代码 & 模型: GitHub (训练 pipeline) · Hugging Face (月度检查点 2013–2024)
本解读页面由 Claude Code 生成,供组会内部讨论使用。